
Bevor Sie die Einrichtung Ihrer Webseite sowie ihre Positionierung in den Suchmaschinen fortsetzen, ist es sehr wichtig, sich zu vergewissern, dass sie zunächst sorgfältig vom Google-Crawler gelesen und somit ordnungsgemäß indexiert wird. Dieser Schritt muss erfolgen, damit sie in den Suchergebnissen erscheint und Besuche verzeichnet werden können.
Noel Patel, Mitbegründer von KISSmetrics, hat kürzlich auf der Webseite des Search Engine Journal 13 Gründe veröffentlicht, die die Ursache für eine schlechte Indexierung (oder eine nicht erfolgte Indexierung) Ihrer Seite durch Google sein könnten. Die Indexierung ist das Eingangstor Ihrer Seite zu den Suchmaschinen. Daher bieten wir Ihnen eine Übersetzung sowie ergänzende Erklärungen zu den verschiedenen Aspekten.
1/ Probleme, die die Indexierung verhindern
1.1/ Google findet Ihre neue Webseite nicht
Falls Sie Ihre Webseite heute oder vor einigen Tagen veröffentlicht haben und sie noch nicht in den Suchergebnissen erscheint, ist dies völlig normal. Dies ist ein vielleicht klassisches „Problem“ bei neuen Seiten, denn Google kann vor der Verzeichnisaufnahme mehrere Tage brauchen. Falls das Problem besteht, melden Sie sich manuell bei Google an. Dadurch können Sie dem zuvorkommen und der Suchmaschine Ihre Präsenz mitteilen.
Außerdem sollten Sie überprüfen, ob Ihre XML-Sitemap generiert wurde und zugänglich ist. Diese erleichtert die Indexierungsarbeit der Suchmaschinen.
Kleiner Tipp: Falls Sie einen Twitter-Account besitzen, tweeten Sie den Link auf Ihre Startseite. Google verfolgt Tweets sichtbar, sodass Ihre Webseite schneller indexiert werden kann als mit dem Anmeldeformular.
1.2/ Eine .htaccess-Datei blockiert die Seite
Eine .htaccess-Datei ist fester Bestandteil einer Webseite und für den Zugang zum World Wide Web auf Ihrem Server. Es handelt sich dabei um eine Konfigurationsdatei der HTTP Apache Server.
Manchmal ist es notwendig, den Zugang zu einem Verzeichnis auf einem Internetserver zu schützen, um zu vermeiden, dass Unbefugte Zugriff darauf haben. Dafür wird ein Stück des Codes in die .htaccess-Datei eingefügt, wodurch die Anzeige der Seite blockiert wird und die Eingabe einer Benutzerkennung und eines Passwortes erforderlich ist: htpasswd. Diese Datei schickt den Crawlern der Suchmaschinen den HTTP-Fehlercode 401 („zum Zugriff auf die Quelle ist eine Authentifizierung notwendig“) mit dem Hinweis, die Seite nicht in ihrer Gänze zu indexieren.
Überprüfen Sie also den Inhalt Ihrer .htaccess-Datei, um Problemen bei der Indexierung vorzubeugen.
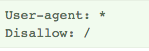
1.3/ Die Datei robots.txt blockiert Ihre Seite
Ein anderer Grund für die nicht gelungene Indexierung Ihrer Seite könnte die Sperrung Ihres Robots-Exclusion-Standard-Protokolls durch die Datei robots.txt sein. Dabei handelt es sich um eine Textdatei, die zum Einsatz kommt, um eine oder mehrere Webpages Ihrer Seite für die Crawler von Suchmaschinen zu sperren. Sie wird in das Stammverzeichnis einer Seite platziert und kann somit das Crawlen Ihrer Seite durch Googlebot (Webcrawler von Google) blockieren.
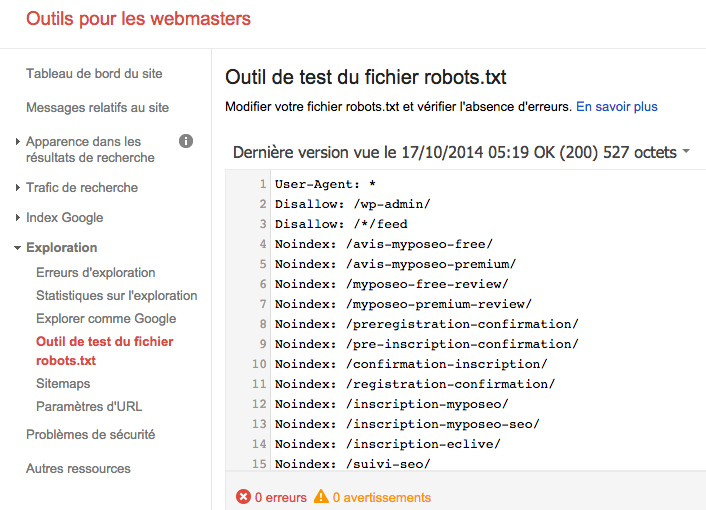
Um dies zu beheben, können Sie in Ihrem GWT-Konto den Status Ihrer robots.txt-Datei kontrollieren und ihn so ändern.
1.4/ Word Press: das Kästchen für Nicht-Indexierung durch Suchmaschinen ist angekreuzt
Zahlreiche Webseiten nutzen heutzutage die Anwendung WordPress. Bei der Erstellung einer Webseite mit WordPress können Sie in den Einstellungen durch das Ankreuzen eines Kästchens eine Funktion aktivieren, durch die die robots.txt-Datei geändert wird. Stellen Sie sicher, dass dieses Kästchen in Ihrem Back Office frei bleibt, damit Ihre Seite indexiert werden kann.
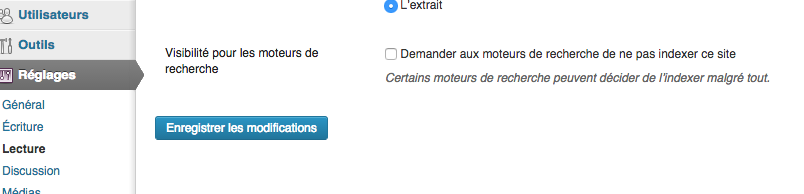
1.5/ Die URLs werden durch ein Meta-Tag blockiert
Es ist möglich, die Anzeige einer Seite in den Google-Suchergebnissen zu verhindern, indem ein Meta-Tag noindex in ihren HTML-Code eingefügt wird. Dieser Code wird zwischen die Tags <head> </head> Ihrer Seite integriert, wodurch den Suchmaschinen mitgeteilt wird, dass die Links der Seite weder indexiert noch verfolgt werden sollen.
<META NAME=”ROBOTS” CONTENT=”NOINDEX, NOFOLLOW”>
Stellen Sie demnach sicher, dass sich keine noindex- oder nofollow-Attribute auf einer oder mehrerer Webpages Ihrer Webseite befinden.
1.6/ Indexierte Seite unter www.
Der erste wichtige Punkt ist die Unterdomäne, unter der Ihre Webseite erstellt wurde. Viele Seiten werden standardmäßig auf der Unterdomäne „www“ gehostet und zu oft wird vergessen, dass http://myposeo.com nicht dieselbe Adresse ist wie http://www.myposeo.com.
Damit Ihre Seite nun unter beiden Adressen zugänglich ist, muss mit einer .htaccess-Datei eine Weiterleitung eingerichtet werden, z.B. von http://myposeo.com zu http://www.myposeo.com. Zum besseren Verständnis dieses Vorgangs empfehlen wir Ihnen, sich die auf blogmotion erbrachte Vorführung anzuschauen.
Um sich anschließend zu vergewissern, dass der Zugang zu Ihrer Seite über die beiden URLs erfolgreich konfiguriert wurde, klicken Sie auf Ihr GWT-Konto (Google Webmaster Tool) und fügen Sie beide Domänen hinzu, damit sie kontrolliert werden:
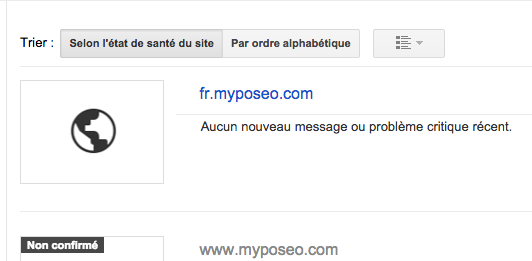
In den Einstellungen von GWT können Sie anschließend die bevorzugte Domäne für den Zugriff auf Ihre Seite auswählen. Diese Domäne (oder vielmehr Unterdomäne) wird von Google zur Anzeige Ihrer Seite in der Suchmaschine ausgewählt.
2/ Probleme, die der sachgemäßen Indexierung oder Wiederindexierung schaden
2.1/ Es wurde keine XML-Sitemap eingerichtet
Ein Grund einer schlechten Indexierung Ihrer Seite durch Google könnte auch eine fehlende XML-Sitemap sein. Durch jenes Protokoll können die Webpages einer Seite aufgezeigt werden, die von den Webcrawlern der Suchmaschinen erfasst werden müssen. So erhält Google Weiterleitungen der Seiten, die auf Ihrer gesamten Webpräsenz vertreten sind. Denken Sie also daran, eine Sitemap zu erstellen und sie via GWT zu verschicken.

2.2/ Es handelt sich um Crawling-Fehler
Die Crawler der Suchmaschinen lesen Ihre Seite und „springen“ von Link zu Link, um ihre Suche fortzusetzen. Manchmal landen Sie dabei in einer Art Sackgasse oder auf Links, die sie auf nicht existierende oder verschobene Seiten weiterleiten. Auf Ihrer Seite befinden sich also eine Vielzahl von „Crawling“-Fehlern (bezieht sich auf das Lesen), d.h. URL-Fehler. Mithilfe Ihres GWT-Kontos können Sie diese erkennen. Wählen Sie Ihre Seite aus und gehen Sie dann auf Crawling-Fehler. Auf dieser Seite werden die URLs präzisiert, die Google nicht crawlen kann oder bei denen ein HTTP-Fehlercode angezeigt wird.
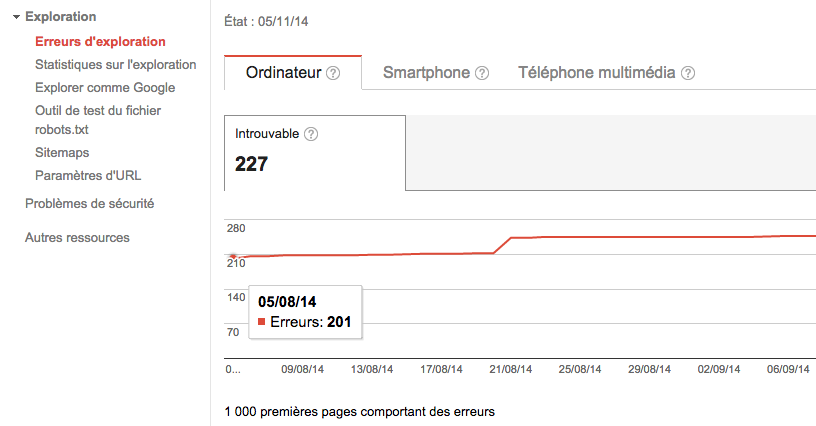
Dann kann es wichtig sein, diejenigen Links von Ihrer Seite zu löschen, die auf nicht existierende Seiten führen bzw. daran zu denken, die nicht existierenden Seiten auf andere, als Ersatz dienende Seiten weiterzuleiten. Laden Sie sich dafür gratis Crawling-Software herunter, wie z.B. Xenu (PC) oder Intregrity (Mac), durch die Sie kaputte Links noch präziser aufspüren können. Das von Webrankinfo empfohlene Tutorial zur Seitenweiterleitung kann ebenfalls nützlich sein.
2.3/ Ähnlicher oder doppelt vorhandener Inhalt (duplicate content)
Es kommt vor, dass sich auf mehreren Webpages derselben Seite der gleiche Inhalt befindet, was als Duplizierung von Inhalten (duplicate content) bezeichnet wird. Dies generiert wiederholt auftretende Suchergebnisse, die Google auszusortieren versucht. Wenn Google zu viele ähnliche Inhalte findet, kann die Crawling-Frequenz verlangsamt werden oder die Seite kann sogar ganz vom Index ausgeschlossen werden.
Wählen Sie zur Fehlerbehebung die Webpage aus, die gespeichert werden soll, und leiten Sie die anderen an diese mit einer 301-Weiterleitung weiter. User und Suchmaschinen werden dann auf die richtige Webpage verwiesen.
Anmerkung: Es gibt „Canonical Tags“, um das Phänomen „duplicate content“ zu bekämpfen. Wenn Sie einen URL festlegen wollen, zu dem man bevorzugt zu einem Inhalt gelangen soll, können Sie dies den Suchmaschinen mitteilen. Taggen Sie dazu die kanonische Seite mit einem Element „link“ rel=’canonical’.
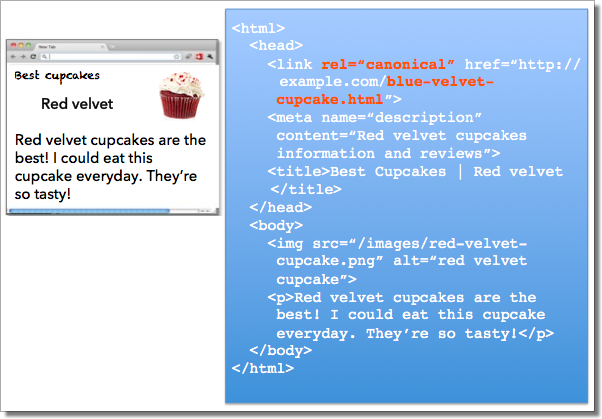
2.4/ Probleme mit AJAX/ JAVASCRIPT
Wenn die Suchmaschinen das JavaScript kaum lesen können und blockiert sind, stoppen sie. In diesem Fall ist es unmöglich, das zu crawlen, was nach Ihrem Script kommt (die Seite, das Menü, andere Webpages…). Falls Sie Ihre JavaScript-Seiten nicht perfekt konfiguriert haben, kann Google die Datenlesung Ihrer Seiten stoppen und somit die Indexierung der Seite begrenzen. Öffnen Sie zur Kontrolle der Ladezeit Ihrer Seite ein Navigationstool wie Firebug oder das ursprüngliche Tool von Google Chrome im Tab „Network“.
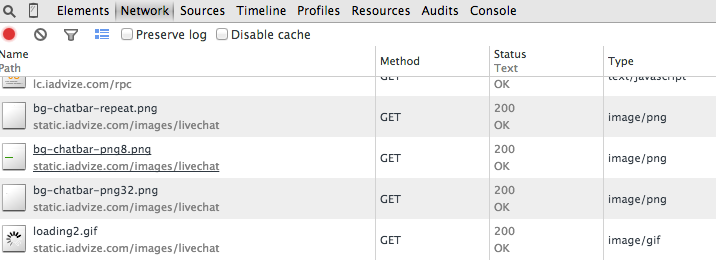
2.5/ Lang andauernde oder zu langsame Ladezeit
Die Ladezeit Ihrer Seiten kann einen sehr bedeutsamen Einfluss auf die Crawler haben, wie im vorherigen Punkt bereits erläutert wurde. Wenn es Google nicht gelingt, auf die verschiedenen Webpages Ihrer Seite zuzugreifen, kann keine „Pause“ gemacht und gewartet werden. Im Gegenteil, es besteht das Risiko, dass Google Ihre Seite verlässt und das Crawling stattdessen auf konkurrierenden Webseiten fortsetzt. Eine schnell ladende Webseite kann sehr viel schneller indexiert werden und zu einer besseren Referenzierung beitragen.
Sie können die Ladezeit Ihrer Seiten durch zahlreiche Tools wie GTmetrix oder dem Add-on Yslow testen. Auf dem Blog SEOmix finden außerdem einen Artikel zu diesem Thema.
Anmerkung: Eine angemessene Ladezeit beträgt nicht mehr als 2-3 Sekunden.
2.6/ Serverprobleme
Google kann dieselben Probleme haben, die Webpages Ihrer Seite zu lesen, wenn Ihr Server nicht die Anforderungen des Crawlers ausführt, um auf die Information zuzugreifen. Stellen Sie zur Behebung dieses Problems sicher, dass Ihr Server solide ist und dem Datenverkehr standhalten kann. Um sich zu vergewissern, dass Ihr Server stets zugänglich ist, können Sie beispielsweise den Gratis-Service Pingdom nutzen, der Sie im Falle eines gesperrten Zugangs Ihrer Seite benachrichtigt.
2.7/ Ihre Seite wurde desindexiert oder mit einer Strafe belegt
Sehr geehrter Eigentümer oder Webmaster dieser Seite…, Wir haben festgestellt, dass bestimmte Webpages Ihrer Seite den Google-Richtlinien für Webmaster zu widersprechen scheinen. Wenden Sie sich für sämtliche Fragen bezüglich der Lösung dieses Problems an unser Hilfeforum für Webmaster. Mit freundlichen Grüßen, Ihr Google-Team für Suchqualität.
Diese Art Nachricht wird verschickt, um anzukündigen, dass eine Webseite von Google desindexiert oder mit einer Strafe belegt wurde. Dies kann passieren, wenn Ihre Webseite nicht den Kriterien der Filter Google Panda und Google Penguin entspricht. Zum Verständnis und zur Analyse der Situation Ihrer Seite empfehlen wir Ihnen, Ihre Webmaster-Tools aufzurufen und dort die Qualitätsrichtlinien von Google zurate zu ziehen. Solch ein Fall ist zwar recht selten, doch sämtliche Webseiten, die eine Netlinking-Strategie (Links) anwenden oder die an ihrer Referenzierungsoptimierung arbeiten, können im Visier von Google sein. Lassen Sie dabei also Vorsicht walten.
Zusammenfassung
Noch einmal: Damit eine Webseite in den Ergebnissen einer Suchmaschine erscheint, muss sie in ihrer Datenbank indexiert sein. Zunächst muss Google mithilfe seiner Crawler in der Lage sein, sie zu finden und sie anschließend lesen zu können. Falls Ihre Seite oder bestimmte Webpages Ihrer Seite nicht indexiert sind, müssten Sie nun die Gründe verstehen. Jetzt kennen Sie sämtliche Elemente, um Ihre Seite zu analysieren und dafür zu sorgen, dass sie gut referenziert und positioniert wird!
Carol-Ann
Marketing manager @myposeo, Community-Manager und Schriftsteller.
- More Posts (664)